《聊天机器人的背后,GPT如何运作?》(2)嵌入和去嵌入矩阵

以 GPT3 为例,什么是 Transformer 和 Attention?
GPT3 中的1750 亿个权重,被组织在大约 28.000 个不同的矩阵中。矩阵被分为 8 个不同类别。 ,接下来就通过介绍着 8 个类别的矩阵,让你了解什么是GPT。
需要区分两个概念:权重(视频中为蓝色或红色)和数据(白色或灰色)。权重就是模型的大脑,是在训练过程中学到的,它们决定了模型的行为模式。
一、嵌入矩阵(Embedding matrix)— 参数 617,558,016
(从这里开始,我们把“Token”简化为“单词”,便于理解)
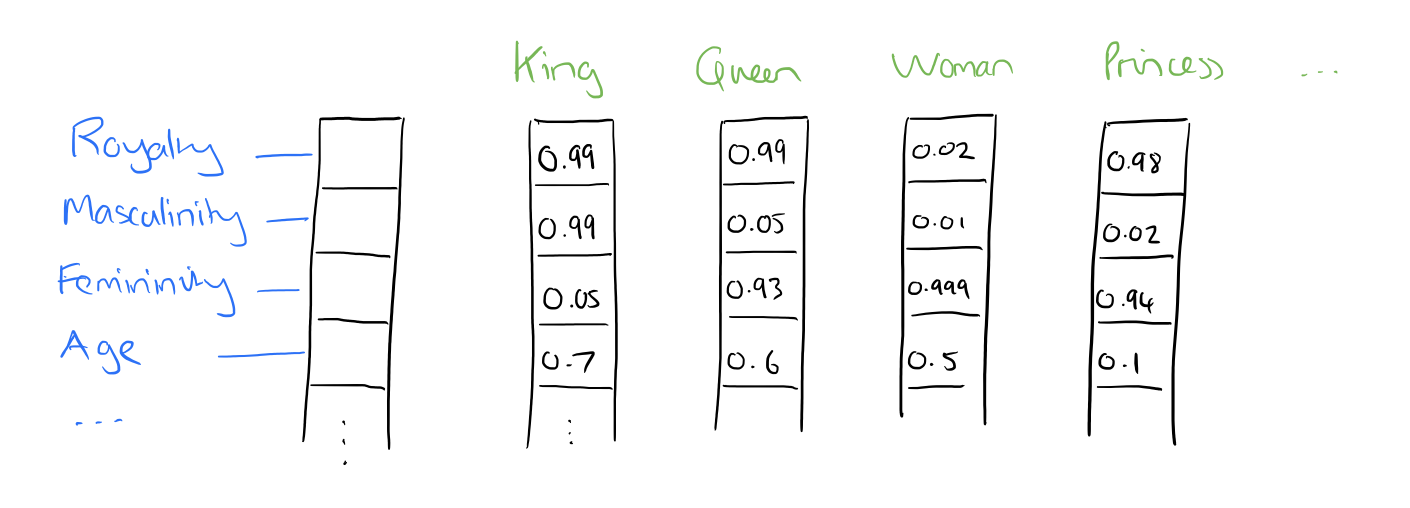
嵌入矩阵,用 【预设词汇库】 为全部的词分配了一个独立的列,嵌入矩阵中的每一列,就对应着一个单词在第一步中转换成的向量。
- 定理一 :在多维空间中,每一个维(方向)都能够传达特定的语义。
- 定理二 :两个向量的点积可以被视为一种衡量他们是否对齐的方法
- 点积为正:两个向量指向方向相似
- 点积为0:两个向量指向方向垂直
- 点积为负:两个向量指向方向相反
- 例子:我们用
cats向量-cat向量,得到语义为“复数程度”的向量,用单数名词点乘这个向量时,获得的值往往为负;复数时,获得值为正。
对于 GPT3 模型,这个嵌入矩阵中
- 包含的词汇量为 50,257
- 嵌入的维度是 12,288
- ==> 相乘后大约有 6.17 亿个权重
被“嵌入”的词只代表了单个词汇,不涉及周围信息,但我们需要它去包含词汇的位置信息,也就是结合必要的上下文。
第一步里,我们使用嵌入矩阵,将输入内容转化为初始向量数组。
接下来,就要让这个初始向量数组 通过网络,使得每一个向量都获得比单个词更丰富更具体的含义。这个网络每次只能处理一定数量的向量,这个数量就是上下文大小( Context Size)
补充:事实上,初始向量数组还包含了每一个单词的位置信息,即他们位于输入内容中的位置
二、去嵌入矩阵(Unembedding Matrix)— 参数 617,558,016 (和嵌入矩阵相同)
- 将上下文(Context)中的最后一个向量,通过和 去嵌入矩阵(Unembedding Matrix) 相乘,映射到包含所有 【预设词汇库】 (想象他是一本动态词典)的 50k 的列表
- 通过一个函数,
softmax,来把列表里面这些值转化成词汇的概率分布
去嵌入矩阵(Unembedding Matrix) ,为我们的老朋友 【预设词汇库】 中的每个单词都分配了一行,每一行包含了与嵌入维度相同数量的元素,被标记为 Wu ,和所有矩阵一样,这个矩阵的初始值是随机的,但在训练过程中,它们会被更新。
softmax:我们希望把最后得到的一串数字,变为代表单词出现的概率,那么这些数字每个都要在0到1之间,并且加起来为1。但是在深度学习的实践中,这些数可能不符合条件(例如值远大于1或者为负数等)。softmax可以把任何一组数字转换成一个有效的分布。当ChatGPT希望调整输出的不稳定性,或者说趣味性时,会涉及到一个参数叫“Temperature”,调整这个“Temperature”其实就是在调整 softmax中的一个t参数,t越大,原本在概率分布中占比较小的数值,就会获得更高的权重。
总结
这篇文章探讨了GPT-3模型是如何借助嵌入矩阵和去嵌入矩阵来处理和生成语言的。它深入揭示了模型中1750亿个权重参数如何分布于28,000个矩阵中,并详细讲述了这些矩阵中的8个类别,尤其是嵌入矩阵和去嵌入矩阵的构造和作用。
记住这些精华点:
- 嵌入矩阵负责将单词转换为向量,这些向量能够在多维空间中表征词语的语义,并通过点积揭示向量间的相似性或区别。
- GPT-3的嵌入矩阵拥有超过6亿个权重,映射了50,257个词汇和12,288维度的向量空间。
去嵌入矩阵的作用是将上下文中的信息映射回预设词汇库,生成下一个词的概率分布,这是GPT-3生成连贯文本的重要环节。 - 重要的softmax函数,将一串数值转换成概率分布,是确定最终输出单词的关键。
通过嵌入和去嵌入矩阵,GPT-3模型将零散的单词赋予了上下文的意义,并且通过复杂的计算过程预测下一个合适的词汇。在深度学习的世界里,这些矩阵和函数扮演着构筑语言理解和生成的基石角色。下一篇我们将介绍Attention is All You Need 中的“Attention”——注意力块。